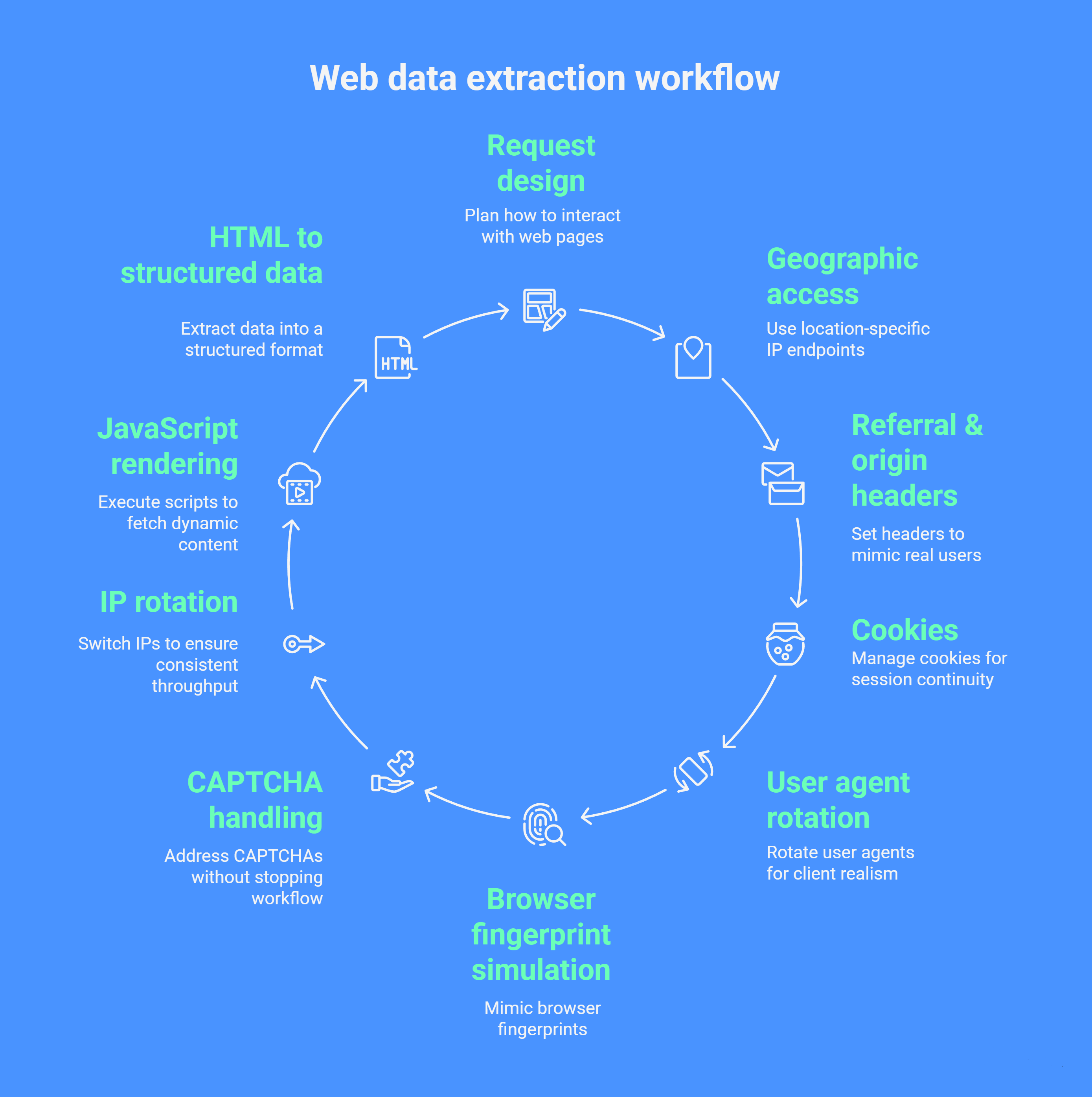
10 pasos prácticos para una recolección eficiente de datos web

Contenido del artículo:
- Diseño de solicitudes
- Acceso geográfico
- Referencias y encabezados de origen
- Gestión de cookies y sesiones
- Rotación de agentes de usuario
- Simulación de huellas del navegador
- Manejo de CAPTCHA
- Rotación de IP
- Renderizado de JavaScript
- HTML a datos estructurados
Diseñar un marco integral para la extracción de datos web en 2026 requiere un flujo de trabajo estructurado. Este artículo describe un proceso de 10 pasos que se puede utilizar con los mejores servicios para escalar la recolección de datos, como Dexodata. Al integrar estas prácticas con soluciones que te permiten comprar proxies residenciales y móviles, los equipos pueden lograr un scraping geo-dirigido eficiente para análisis posteriores, BI o pipelines de IA.
-
Diseño de solicitudes
Un diseño de solicitud establece las bases para la recolección de datos web a gran escala al aislar la lógica de solicitud de las capas de análisis y extracción. Este paso trata sobre cómo tu programa interactúa con las páginas web. Puedes hacer solicitudes HTTP simples (como obtener HTML) o usar un navegador sin cabeza para interactuar con sitios pesados en JavaScript:
-
- Usa clientes HTTP para contenido estático (Python “Requests”, Node.js “Axios”).
- Usa navegadores sin cabeza para sitios dinámicos (Playwright, Puppeteer).
-
-
Acceso geográfico
Algunos sitios web muestran contenido basado en tu IP. Los puntos finales de IP específicos de ubicación permiten el scraping geo-dirigido para diferentes regiones, como Europa, EE. UU., Rusia o ciudades específicas. Se puede usar para comparar precios y disponibilidad de productos, o realizar análisis comparativos.
Para fines de monitoreo:
-
- Registra métricas de ubicación para responder si diferentes geos producen diferentes versiones de contenido.
- Mantén metadatos sobre la geolocalización de IP resuelta para cada solicitud.
-
-
Referencias y encabezados de origen
Los encabezados HTTP como “Referer”, “Origin” y “Accept-Language” indican al sitio web de dónde provino la solicitud y el idioma del navegador. Configurar correctamente estos encabezados hace que tus solicitudes parezcan más reales. Una gestión efectiva de encabezados mejora la consistencia y confiabilidad de los proxies rotativos con alta disponibilidad al realizar operaciones a gran escala.
Usa plantillas de encabezados de navegador real y monitorea encabezados que consistentemente desencadenan anomalías (404, CAPTCHA, redirección).
-
Gestión de cookies y sesiones
Las cookies almacenan información de sesión como tokens de inicio de sesión, preferencias de usuario o banderas de consentimiento. Sin gestión de cookies, las solicitudes repetidas pueden fallar o devolver datos incompletos. Las cookies juegan un papel crítico en la continuidad de la sesión, la autenticación y el acceso al contenido.
-
- Usa frascos de cookies por sesión para guardar y reproducir cookies por sesión.
- Separa las cookies por tarea para evitar conflictos.
-
-
Rotación de agentes de usuario
La cadena “User-Agent” (UA) identifica el dispositivo y el navegador. Influye en cómo los servidores clasifican tu cliente. Cuando se combina con proxies rotativos con alta disponibilidad, la gestión de UA aumenta significativamente la resiliencia durante el scraping geo-dirigido.
-
- Mantén un grupo de UAs de navegador actualizados (escritorio, móvil).
- Combina la rotación de UA con otros vectores de identidad (geolocalización de IP, tamaño de vista, zona horaria) para fortalecer el realismo del cliente.
-
-
Simulación de huellas del navegador
Los sitios web a veces utilizan huellas del navegador (resolución de pantalla, fuentes, características de WebGL) para detectar herramientas automatizadas. Imitar huellas significa hacer que las solicitudes parezcan consistentes con navegadores reales.
Puedes consultar los atributos del navegador para obtener información adicional para tus scrapers. -
Manejo de CAPTCHA
Los CAPTCHA previenen el acceso automatizado. Cuando los sitios implementan desafíos interactivos, necesitas manejarlos sin detener el flujo de trabajo. El CAPTCHA se maneja mejor cuando no se activa: su resolución es uno de los mayores desafíos para la recolección de datos web a gran escala, incluso con herramientas de IA. Cuando es inevitable, las técnicas incluyen:
-
- Solucionadores automáticos.
- Verificación humana en el proceso.
- Puntos finales de API alternativos cuando sea posible.
-
-
Rotación de IP
Si una solicitud falla, tu sistema debe reintentar automáticamente y, si es necesario, cambiar a otra IP. Esto asegura un rendimiento constante. Estas prácticas sustentan proxies rotativos con alta disponibilidad y rendimiento acumulativo para cargas de trabajo grandes.
-
- Usa retroceso exponencial + jitter para reintentos y evitar tormentas de reintentos.
- Mantén métricas por IP / punto final: tasa de éxito, latencia, tipos de error.
- Rota IPs automáticamente cuando se cumplen los umbrales de fallo.
-
-
Renderizado de JavaScript
Los sitios web modernos dependen cada vez más de la lógica del lado del cliente para obtener y mostrar contenido. Si tu sistema solo recopila HTML sin ejecutar scripts, a menudo perderás la mayor parte de los datos reales. Las soluciones pueden incluir herramientas basadas en navegador o sin navegador:
-
- Para APIs simples: Algunas páginas obtienen datos de APIs en segundo plano. Pueden ser interceptadas para reutilizar URLs de puntos finales directamente en tu flujo de trabajo.
- Para UIs completas: Usa herramientas que emulen el comportamiento completo del navegador y ejecuten JavaScript como Playwright o Puppeteer.
-
-
HTML a datos estructurados
Una vez que se obtiene el contenido, necesitas extraer datos en un formato estructurado (JSON, CSV, base de datos) para análisis. La extracción es donde el contenido bruto se convierte en datos utilizables.
Para asegurar un rendimiento estable y tolerancia a fallos durante el scraping a gran escala, la rotación de IP debe regirse por reglas explícitas de reintento y gestión de salud:-
- Usa selectores CSS / XPath o analizadores semánticos.
- Mapea campos en registros tipados (fecha, precio, ubicación, identificador) y valida a través de un esquema.
- Monitorea fallos de extracción, duplicados, campos faltantes; alerta sobre desviaciones de esquema.
Con Dexodata, puedes comprar proxies residenciales y móviles y combinarlos con acceso consciente de la geolocalización, gestión de huellas digitales y otras técnicas para construir pipelines confiables y escalables. Ofrecemos millones de IPs de pares reales en blanco de más de 100 países, incluidos Alemania, Francia, Reino Unido y Rusia. Los nuevos usuarios pueden solicitar una prueba gratuita y probar proxies de forma gratuita.
-